
Large Language Models (LLMs) haben in den letzten Jahren große Fortschritte gemacht und die Art und Weise revolutioniert, wie wir künstliche Intelligenz (KI) nutzen. Diese Modelle sind darauf ausgelegt, menschliche Sprache zu verstehen und zu erzeugen, und sie bieten eine Vielzahl von Möglichkeiten, die weit über einfache Textverarbeitung hinausgehen. Doch was genau sind Large Language Models, wie funktionieren sie, und welche Herausforderungen und Chancen bringen sie mit sich?
Was sind Large Language Models?
Large Language Models (LLMs) sind hochentwickelte KI-Systeme, die auf maschinellem Lernen basieren und speziell dafür entwickelt wurden, natürliche Sprache zu verstehen, zu verarbeiten und zu generieren. Sie sind in der Lage, Texte in verschiedenen Sprachen zu analysieren, komplexe Kontexte zu erfassen und Inhalte zu erstellen, die oft nicht von menschlich geschriebenen Texten zu unterscheiden sind. Bekannte Beispiele für LLMs sind OpenAIs GPT-3 und GPT-4 oder Googles BERT.
Was LLMs von traditionellen KI-Ansätzen unterscheidet, ist ihre enorme Größe und Komplexität. Diese Modelle bestehen aus Milliarden bis hin zu Hunderten von Milliarden von Parametern, also den einstellbaren Variablen, die das Verhalten des Modells bestimmen. Diese Größe ermöglicht es ihnen, eine unglaubliche Tiefe und Breite an Informationen zu verarbeiten und anzuwenden.
Wie funktionieren Large Language Models?

Um zu verstehen, wie LLMs arbeiten, ist es wichtig, einen Blick auf ihre technischen Grundlagen zu werfen. Der Prozess, der hinter ihrer Funktionsweise steht, ist sowohl faszinierend als auch komplex.
Die Grundlagen von neuronalen Netzwerken
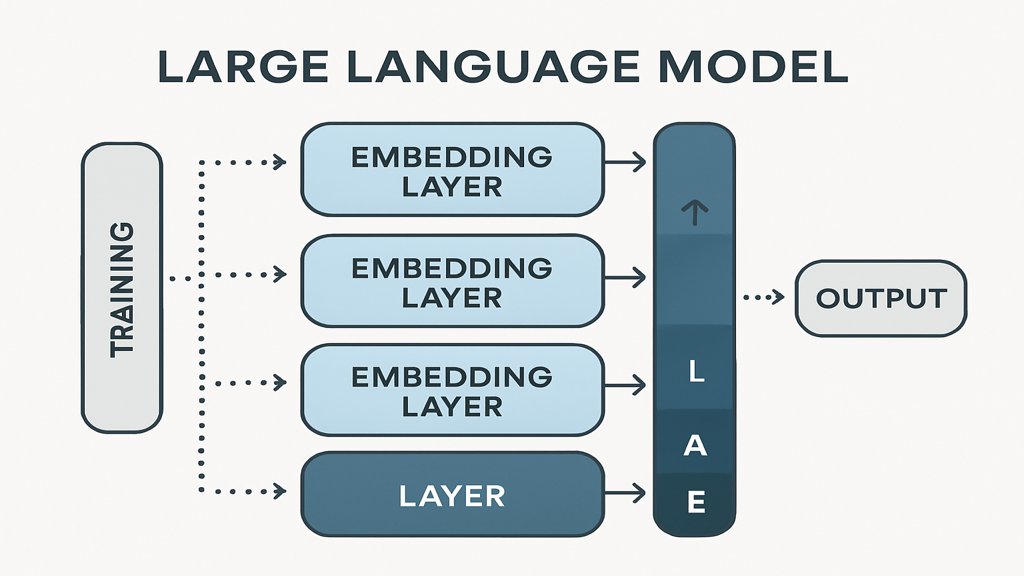
LLMs basieren auf neuronalen Netzwerken, einer Art von Computermodellen, die von der Struktur und Funktion des menschlichen Gehirns inspiriert sind. Ein neuronales Netzwerk besteht aus mehreren Schichten von „Neuronen“, die miteinander verbunden sind. Diese Neuronen nehmen Eingaben auf, verarbeiten sie und geben Ergebnisse aus.
Bei Large Language Models handelt es sich meistens um sogenannte „tiefe neuronale Netzwerke“, die viele Schichten umfassen. Besonders wichtig sind dabei Transformer-Architekturen, die es den Modellen ermöglichen, Kontextinformationen effizient zu verarbeiten und Beziehungen zwischen Wörtern in einem Satz zu verstehen. Einen tieferen Einblick in diese Technologie bietet unser Artikel über das Transformer Modell einfach erklärt.
Training und Datenverarbeitung
Um ein Large Language Model zu trainieren, wird es mit riesigen Mengen an Textdaten gefüttert. Diese Daten stammen aus unterschiedlichsten Quellen, wie Büchern, Webseiten, wissenschaftlichen Artikeln oder sozialen Medien. Ziel des Trainings ist es, dem Modell beizubringen, Muster und Strukturen in der Sprache zu erkennen, sodass es Vorhersagen über den nächsten Wortbestandteil treffen kann.
Während des Trainingsprozesses passt das Modell seine Parameter kontinuierlich an, um die Genauigkeit zu verbessern. Der gesamte Prozess erfordert enorme Rechenleistung und oft Wochen oder Monate an Rechenzeit.
Modelle und Architekturen
Die Architektur eines LLM bestimmt, wie es Informationen verarbeitet. Ein beliebtes Beispiel ist der Transformer, der die Grundlage für viele moderne LLMs bildet. Diese Transformer-Modelle nutzen Mechanismen wie „Selbstaufmerksamkeit“, um Wörter in einem Satz im Kontext ihrer Nachbarn zu analysieren.
Ein weiteres Merkmal moderner LLMs ist ihre Skalierbarkeit. Je mehr Parameter ein Modell hat, desto besser kann es komplexe Aufgaben bewältigen. Allerdings bringt diese Größe auch Herausforderungen mit sich, wie die Notwendigkeit leistungsfähiger Hardware und umfangreicher Daten.
Anwendungsbereiche von Large Language Models
Die Vielseitigkeit von Large Language Models hat zu ihrer breiten Anwendung in verschiedenen Bereichen geführt. Sie bieten innovative Lösungen für alltägliche und geschäftliche Herausforderungen.
KI-gestützte Kommunikation
LLMs werden häufig in Kommunikationsanwendungen eingesetzt. Chatbots und virtuelle Assistenten wie Alexa oder Google Assistant nutzen diese Modelle, um natürliche Gespräche zu führen, Fragen zu beantworten oder sogar personalisierte Empfehlungen zu geben.
Automatisierte Datenanalyse
Ein weiterer wichtiger Anwendungsbereich ist die Datenanalyse. LLMs können große Mengen an unstrukturierten Daten durchsuchen und relevante Informationen extrahieren. Dies ist besonders nützlich in Bereichen wie der Medizin oder der Finanzanalyse, wo große Textmengen schnell und präzise verarbeitet werden müssen.
Content-Erstellung und kreative Prozesse
LLMs haben auch kreative Branchen revolutioniert. Sie können Artikel, Geschichten, Gedichte und sogar Computerprogramme schreiben. Dabei unterstützen sie Autoren, Journalisten und Kreative bei der Ideenfindung und der Erstellung von Inhalten. Wenn Sie mehr über KI-gestützte Content-Erstellung erfahren möchten, empfehlen wir unseren Beitrag über KI in der Content Erstellung.
Die Herausforderungen von Large Language Models
Trotz ihrer beeindruckenden Fähigkeiten stehen LLMs vor einer Reihe von Herausforderungen, die es zu bewältigen gilt.
Ethik und Bias in KI
Ein großes Problem von LLMs ist der potenzielle Bias (Voreingenommenheit) in den Trainingsdaten. Da die Modelle auf menschlich erstellten Texten basieren, können sie bestehende Vorurteile und Diskriminierungen übernehmen und verstärken.
Rechenleistung und Energieverbrauch
Die Entwicklung und der Betrieb von LLMs erfordern enorme Rechenressourcen. Dies führt zu einem hohen Energieverbrauch, der Fragen hinsichtlich der Umweltverträglichkeit aufwirft.
Datenschutz und Sicherheit
Da LLMs oft auf großen Mengen an öffentlich verfügbaren Daten trainiert werden, besteht die Gefahr, dass sensible oder private Informationen im Modell gespeichert werden. Dies wirft Fragen zum Datenschutz auf. Weiterführende Informationen hierzu finden Sie in unserem Artikel über die DSGVO für Unternehmen.
Die Zukunft von Large Language Models

Trotz der aktuellen Herausforderungen bleibt die Zukunft von LLMs vielversprechend, da kontinuierlich an ihrer Verbesserung gearbeitet wird.
Neue Entwicklungen in der Forschung
Die Forschung im Bereich LLMs entwickelt sich rasant weiter. Wissenschaftler arbeiten an effizienteren Trainingsmethoden, kleineren und dennoch leistungsstarken Modellen sowie an Ansätzen, um Bias und ethische Probleme zu minimieren.
Integration in den Alltag
Mit der Zeit werden LLMs immer stärker in unseren Alltag integriert. Von personalisierten Lernplattformen bis hin zu intelligenten Haushaltsgeräten – die Möglichkeiten sind nahezu endlos.
Potenzielle Risiken und Chancen
Natürlich bringt die zunehmende Verbreitung von LLMs auch Risiken mit sich, wie den Missbrauch der Technologie oder die Abhängigkeit von KI. Gleichzeitig bieten sie enorme Chancen, etwa in der Bildung, der Wissenschaft oder der Gesundheitsversorgung. Die Herausforderung wird darin bestehen, diese Chancen zu nutzen, ohne die Risiken zu vernachlässigen.
Large Language Models sind zweifellos eine der aufregendsten Entwicklungen im Bereich der künstlichen Intelligenz. Ihre Fähigkeiten und ihr Potenzial sind beeindruckend, doch es bedarf eines verantwortungsvollen Umgangs, um ihre Vorteile voll auszuschöpfen und gleichzeitig ihre Risiken zu minimieren. Wenn Sie tiefer in die Grundlagen eintauchen möchten, besuchen Sie unseren Artikel über Was ist Generative KI.
FAQ zum Thema Large language models (llms)
Was sind Large Language Models?
Large Language Models (LLMs) sind KI-Modelle, die auf der Verarbeitung natürlicher Sprache basieren und große Mengen an Textdaten analysieren können, um menschenähnliche Antworten zu generieren.
Welche Anwendungen haben Large Language Models?
LLMs werden in Chatbots, Übersetzungssoftware, Content-Erstellung, Datenanalyse und vielen anderen Bereichen eingesetzt.
Wie sicher sind Large Language Models?
LLMs können Sicherheitsrisiken bergen, wie z.B. die Generierung falscher Informationen oder die Verletzung von Datenschutzrichtlinien. Eine verantwortungsvolle Nutzung ist entscheidend.


