
Klassifikationsalgorithmen sind ein zentraler Bestandteil des maschinellen Lernens. Sie werden verwendet, um Daten in verschiedene Kategorien einzuteilen. Dabei handelt es sich um mathematische Modelle, die basierend auf bekannten Daten sogenannte Labels oder Klassen vorhersagen. Ein einfaches Beispiel wäre ein Algorithmus, der E-Mails als „Spam“ oder „Nicht-Spam“ klassifiziert. Solche Algorithmen sind besonders hilfreich, wenn Entscheidungen auf Basis großer Datenmengen getroffen werden müssen.
Wie funktionieren Klassifikationsalgorithmen?
Klassifikationsalgorithmen arbeiten, indem sie Muster in Daten erkennen. Diese Muster werden genutzt, um neue, unbekannte Daten zu klassifizieren. Der Prozess kann in mehreren Schritten erklärt werden, die wir im Folgenden betrachten.
Supervised Learning: Die Basis der Klassifikation
Die meisten Klassifikationsalgorithmen basieren auf dem Konzept des Supervised Learning, was übersetzt „überwachtes Lernen“ bedeutet. Hierbei wird der Algorithmus mithilfe eines Datensatzes trainiert, der aus Eingabedaten (Features) und den dazugehörigen richtigen Ergebnissen (Labels) besteht. Der Algorithmus lernt aus diesen Beispielen, um später ähnliche Entscheidungen für neue Daten treffen zu können.
Trainingsdaten und Modellbildung
Der erste Schritt besteht darin, den Algorithmus mit Trainingsdaten zu füttern. Diese Daten enthalten sowohl Eingabewerte als auch die erwarteten Ausgaben. Zum Beispiel könnte ein Algorithmus mit Bildern von Katzen und Hunden trainiert werden, die jeweils korrekt beschriftet sind. Der Algorithmus analysiert die Merkmale dieser Bilder, wie Farbe, Form oder Textur, um ein Modell zu erstellen. Dieses Modell wird dann verwendet, um neue Bilder zu klassifizieren.
Bewertung der Genauigkeit
Nach der Modellbildung muss die Genauigkeit des Algorithmus bewertet werden. Dies geschieht durch Testdaten, die nicht im Trainingsprozess verwendet wurden. Verschiedene Metriken wie Genauigkeit, Präzision und Recall helfen dabei, die Leistung des Modells zu messen. Eine hohe Genauigkeit zeigt, dass der Algorithmus in der Lage ist, die meisten neuen Daten korrekt zu klassifizieren.
Anwendungsbereiche von Klassifikationsalgorithmen

Klassifikationsalgorithmen finden in vielen Bereichen Anwendung. Sie sind entscheidend für die Automatisierung und Verbesserung von Prozessen in verschiedenen Branchen.
Medizinische Diagnosen
In der Medizin helfen Klassifikationsalgorithmen, Krankheiten zu diagnostizieren. Zum Beispiel können sie anhand von Patientendaten wie Alter, Blutwerten oder Symptomen Vorhersagen über mögliche Krankheiten treffen. Solche Systeme werden häufig als Unterstützung für Ärzte genutzt, um Diagnosen schneller und präziser zu stellen.
Spam-Filterung
Ein klassisches Beispiel ist die Filterung von Spam-E-Mails. Hierbei analysiert der Algorithmus Merkmale wie Absender, Betreff oder bestimmte Schlüsselwörter in der E-Mail. Basierend auf diesen Informationen entscheidet er, ob eine Nachricht im Posteingang oder im Spam-Ordner landet.
Bildklassifikation
In der Bildverarbeitung werden Klassifikationsalgorithmen genutzt, um Objekte auf Bildern zu erkennen. Ein Beispiel ist die Gesichtserkennung, bei der Algorithmen Gesichter von Personen identifizieren und kategorisieren. Diese Technologie wird unter anderem in Sicherheitsanwendungen oder in sozialen Medien verwendet.
Kundensegmentierung
Im Marketing helfen Klassifikationsalgorithmen dabei, Kunden in Gruppen einzuteilen. Basierend auf Daten wie Kaufverhalten, Alter oder Interessen können Unternehmen gezielte Werbekampagnen entwickeln, die auf die Bedürfnisse bestimmter Kundengruppen zugeschnitten sind. Ein Überblick über die Anwendungsmöglichkeiten von Machine Learning im Marketing bietet weitere Einblicke.
Beispiele für Klassifikationsalgorithmen

Es gibt verschiedene Typen von Klassifikationsalgorithmen, die je nach Anwendungsfall eingesetzt werden. Hier sind einige der bekanntesten.
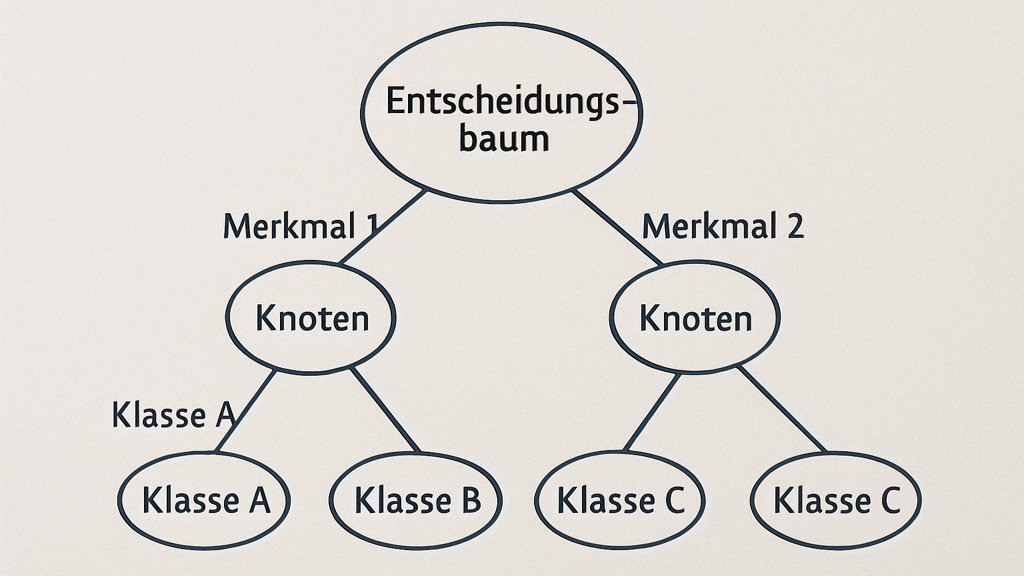
Entscheidungsbäume
Entscheidungsbäume sind leicht verständliche Algorithmen, die Entscheidungen auf Basis einer Baumstruktur treffen. Jeder Knoten im Baum stellt eine Frage zu den Eingabedaten, und die Zweige führen zu einer Entscheidung oder einer weiteren Frage. Sie sind besonders nützlich, wenn Interpretierbarkeit wichtig ist.
Naive Bayes-Algorithmen
Naive Bayes-Algorithmen basieren auf Wahrscheinlichkeitsberechnungen und verwenden den Satz von Bayes. Sie setzen voraus, dass Merkmale unabhängig voneinander sind, was oft nicht der Fall ist, aber dennoch erstaunlich gute Ergebnisse liefert. Sie werden häufig in der Textklassifikation, wie Spam-Filtern, eingesetzt.
Support Vector Machines (SVM)
Support Vector Machines trennen Datenpunkte in einem Raum durch eine sogenannte Hyperplane. Ziel ist es, die Daten so zu trennen, dass der Abstand zwischen den Klassen möglichst groß ist. SVMs sind besonders effektiv, wenn die Daten klar voneinander getrennt sind.
Neuronale Netze
Neuronale Netze sind inspiriert vom menschlichen Gehirn und bestehen aus Schichten von künstlichen Neuronen. Sie sind besonders leistungsfähig bei komplexen Aufgaben wie Bilderkennung oder Spracherkennung. Durch ihre Vielseitigkeit und Genauigkeit werden sie in vielen Bereichen eingesetzt. Weitere Details zu ihrer Funktionsweise finden Sie unter Neuronale Netze einfach erklärt.
Vor- und Nachteile von Klassifikationsalgorithmen
Wie jede Technologie haben auch Klassifikationsalgorithmen ihre Stärken und Schwächen.
Vorteile: Effizienz und Präzision
Ein großer Vorteil von Klassifikationsalgorithmen ist ihre Fähigkeit, große Datenmengen effizient zu verarbeiten. Sie können komplexe Muster und Zusammenhänge erkennen, die für das menschliche Auge nicht offensichtlich sind. Zudem können sie Entscheidungen mit hoher Präzision treffen, wenn sie gut trainiert sind.
Nachteile: Datenqualität und Overfitting
Ein Nachteil ist die Abhängigkeit von der Datenqualität. Schlechte oder unvollständige Daten können zu fehlerhaften Ergebnissen führen. Zudem neigen einige Algorithmen zum sogenannten Overfitting. Das bedeutet, dass sie zu sehr auf die Trainingsdaten abgestimmt sind und bei neuen Daten schlechter abschneiden.
Fazit: Klassifikationsalgorithmen im Überblick
Klassifikationsalgorithmen sind unverzichtbar für viele moderne Anwendungen. Sie helfen, Daten effizient zu analysieren und fundierte Entscheidungen zu treffen. Ob in der Medizin, im Marketing oder in der Bildverarbeitung – ihre Einsatzmöglichkeiten sind nahezu unbegrenzt. Dennoch erfordern sie sorgfältige Datenvorbereitung und eine regelmäßige Überprüfung, um ihre volle Leistungsfähigkeit auszuschöpfen. Die Wahl des richtigen Algorithmus hängt immer vom spezifischen Anwendungsfall und den verfügbaren Daten ab.
Einen tiefergehenden Überblick über Machine Learning für Manager finden Sie hier: Machine Learning für Manager.
FAQ zum Thema Klassifikationsalgorithmen
Was sind Klassifikationsalgorithmen?
Klassifikationsalgorithmen sind Methoden des maschinellen Lernens, die Daten in vordefinierte Kategorien einteilen. Sie werden häufig in der KI und Datenanalyse eingesetzt.
Welche Arten von Klassifikationsalgorithmen gibt es?
Zu den häufigsten gehören Entscheidungsbäume, naive Bayes-Algorithmen, k-Nearest Neighbor (k-NN), Support Vector Machines (SVM) und neuronale Netze.
Wo werden Klassifikationsalgorithmen angewendet?
Sie werden in Bereichen wie Spam-Erkennung, Bildklassifikation, medizinische Diagnosen und Kundensegmentierung eingesetzt.


