
Transformer Modelle haben die Welt der künstlichen Intelligenz (KI) revolutioniert und sind heute aus zahlreichen Anwendungsbereichen nicht mehr wegzudenken. Sie sind insbesondere im Bereich der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) führend. Doch was genau steckt hinter dieser Technologie? In diesem Artikel erklären wir das Transformer Modell einfach und verständlich.
Was ist ein Transformer Modell?

Ein Transformer Modell ist eine Architektur für neuronale Netzwerke, die speziell für die Verarbeitung von Sequenzen entwickelt wurde. Es wurde 2017 von Forschern bei Google in dem bahnbrechenden Paper „Attention is All You Need“ vorgestellt. Das Modell löste viele Herausforderungen in der Verarbeitung natürlicher Sprache, vor allem durch den innovativen Einsatz des sogenannten „Self-Attention“-Mechanismus. Anders als frühere Modelle wie rekurrente neuronale Netzwerke (RNNs) oder Long Short-Term Memory Netzwerke (LSTMs) können Transformer Modelle Sequenzen parallel verarbeiten. Dies macht sie extrem effizient und leistungsstark.
Wie funktioniert ein Transformer Modell?
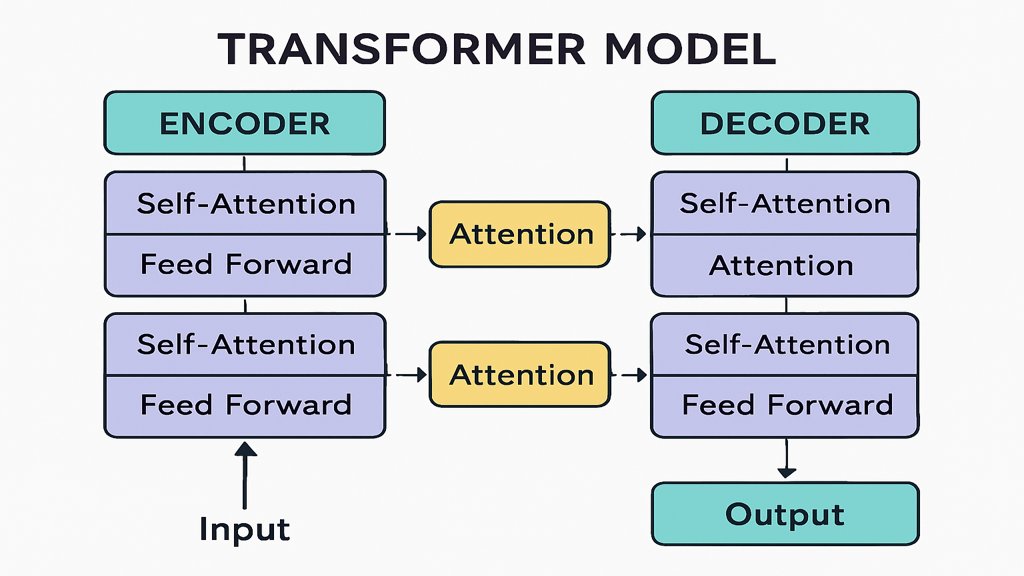
Die Funktionsweise eines Transformer Modells basiert auf einer innovativen Kombination verschiedener Komponenten. Zu den zentralen Konzepten gehören die Encoder-Decoder-Struktur, der Self-Attention-Mechanismus und die Verwendung von Embeddings. Diese Komponenten arbeiten zusammen, um Eingabedaten wie Text oder Bilder zu analysieren und in eine gewünschte Ausgabe zu transformieren.
Die Encoder-Decoder-Struktur
Die Transformer Architektur besteht aus zwei Hauptkomponenten: einem Encoder und einem Decoder. Der Encoder nimmt die Eingabedaten entgegen und verarbeitet sie in mehreren Schritten, um ein abstraktes Repräsentationsformat zu erzeugen. Dieses Format wird dann an den Decoder weitergegeben, der es nutzt, um die gewünschte Ausgabe zu erzeugen, beispielsweise einen übersetzten Text oder eine Antwort auf eine Frage.
Ein Encoder besteht aus mehreren Schichten, die jeweils aus einem Self-Attention-Mechanismus und einem Feedforward-Netzwerk bestehen. Der Decoder hat eine ähnliche Struktur, ergänzt durch einen Mechanismus, der die Ausgabe des Encoders berücksichtigt. Diese Struktur ermöglicht es, sowohl die Eingabedaten als auch den Kontext der Aufgabe effizient zu berücksichtigen.
Self-Attention: Der Schlüssel zur Effizienz
Der Self-Attention-Mechanismus ist das Herzstück des Transformer Modells. Er analysiert, wie verschiedene Teile der Eingabesequenz miteinander in Beziehung stehen. Dadurch kann das Modell wichtige Abhängigkeiten zwischen Wörtern oder anderen Elementen einer Sequenz erkennen – unabhängig davon, wie weit sie voneinander entfernt sind.
Ein Beispiel: In einem Satz wie „Das Buch, das ich gestern gekauft habe, ist spannend“ erkennt das Modell, dass „Buch“ und „spannend“ inhaltlich zusammengehören, auch wenn sie nicht direkt nebeneinanderstehen. Diese Fähigkeit macht Transformer Modelle besonders leistungsfähig bei Aufgaben wie maschineller Übersetzung oder Textzusammenfassung.
Die Rolle von Embeddings
Embeddings sind numerische Darstellungen von Wörtern oder anderen Eingabedaten in einem hochdimensionalen Raum. Sie dienen dazu, die Bedeutung von Wörtern in einer Form darzustellen, die für ein neuronales Netzwerk verständlich ist. Im Transformer Modell werden Embeddings mit Positionsinformationen kombiniert, um die Reihenfolge der Daten in der Sequenz zu berücksichtigen.
Diese Positionsinformationen sind wichtig, da Transformer Modelle Sequenzen parallel verarbeiten und daher keine natürliche Reihenfolge wie in RNNs berücksichtigen können. Die Kombination aus Word Embeddings und Positionsinformationen stellt sicher, dass das Modell die Reihenfolge und die Bedeutung der Eingabedaten korrekt interpretiert.
Anwendungsbereiche von Transformer Modellen

Transformer Modelle haben eine Vielzahl von Anwendungen, die weit über die Verarbeitung natürlicher Sprache hinausgehen. Hier sind einige der wichtigsten Einsatzgebiete:
Maschinelle Übersetzung
Eines der bekanntesten Einsatzgebiete von Transformer Modellen ist die maschinelle Übersetzung. Dienste wie Google Translate nutzen Transformer-basierte Architekturen, um Texte von einer Sprache in eine andere zu übersetzen. Dank des Self-Attention-Mechanismus können diese Modelle den Kontext eines Satzes besser erfassen, was zu präziseren Übersetzungen führt.
Textgenerierung und Chatbots
Transformer Modelle sind auch die Grundlage für viele moderne Textgenerierungsanwendungen, wie z. B. Chatbots. Modelle wie GPT (Generative Pre-trained Transformer) können menschenähnliche Antworten generieren, indem sie den Kontext eines Gesprächs analysieren. Sie kommen in Kundenservice-Tools, virtuellen Assistenten und kreativen Schreibanwendungen zum Einsatz.
Optionaler Kür-Link hinzugefügt: Ein verwandtes Thema ist die KI in der Content Erstellung, die Transformer-Modelle für automatisierte Textprozesse nutzt.
Bildverarbeitung mit Vision Transformers
Obwohl Transformer Modelle ursprünglich für Textaufgaben entwickelt wurden, haben sie inzwischen auch in der Bildverarbeitung Einzug gehalten. Vision Transformers (ViT) nutzen die Transformer-Architektur, um Bilder zu analysieren und Aufgaben wie Bilderkennung oder Objekterkennung zu erfüllen. Sie konkurrieren inzwischen erfolgreich mit traditionellen Convolutional Neural Networks (CNNs) in diesem Bereich.
Vorteile und Grenzen von Transformer Modellen
Transformer Modelle bieten zahlreiche Vorteile. Sie sind extrem flexibel und können auf eine Vielzahl von Aufgaben angepasst werden. Ihre Fähigkeit, Sequenzen parallel zu verarbeiten, macht sie effizienter als frühere Modelle. Zudem sind sie in der Lage, komplexe Zusammenhänge innerhalb von Daten zu analysieren.
Allerdings gibt es auch Grenzen. Transformer Modelle benötigen große Datenmengen und Rechenressourcen, um effektiv zu funktionieren. Dies kann ihre Anwendung in Bereichen mit begrenzten Daten oder Hardware-Einschränkungen erschweren. Außerdem können sie manchmal „halluzinieren“, d. h. falsche oder unlogische Ergebnisse liefern, insbesondere bei komplexen Aufgaben.
Ein nützlicher Bezugspunkt zu diesem Thema ist die Risiken von Generativer KI, die auf mögliche Fehlerquellen und Gefahren eingeht.
Die Zukunft der Transformer Modelle in der KI
Die Entwicklung von Transformer Modellen steht noch am Anfang, und die Zukunft verspricht spannende Fortschritte. Forscher arbeiten daran, die Modelle effizienter und weniger ressourcenintensiv zu machen. Gleichzeitig wird ihre Anwendung auf neue Bereiche wie Wissenschaft, Medizin und kreative Künste ausgeweitet.
Ein vielversprechender Ansatz ist die Kombination von Transformer Modellen mit anderen Technologien, wie beispielsweise Graph Neural Networks oder Reinforcement Learning. Ziel ist es, die Stärken verschiedener Ansätze zu bündeln und so noch leistungsfähigere KI-Systeme zu entwickeln.
Zusammenfassend lässt sich sagen, dass Transformer Modelle eine zentrale Rolle in der Weiterentwicklung der künstlichen Intelligenz spielen. Ihre Flexibilität und Leistungsfähigkeit machen sie zu einem unverzichtbaren Werkzeug für die Lösung komplexer Probleme.
Ein umfassender Überblick über die Grundlagen der KI findet sich unter Was ist Generative KI, wo die Bedeutung solcher Modelle im Gesamtkontext erläutert wird.
FAQ zum Thema Transformer modell einfach erklärt
Was ist ein Transformer Modell?
Ein Transformer Modell ist eine Architektur für maschinelles Lernen, die besonders in der Verarbeitung natürlicher Sprache (NLP) eingesetzt wird. Es nutzt Mechanismen wie Self-Attention, um Kontextinformationen effizient zu verarbeiten.
Welche Vorteile bietet das Transformer Modell?
Transformer Modelle sind effizient, skalierbar und ermöglichen die Verarbeitung großer Datenmengen. Sie sind besonders geeignet für Aufgaben wie maschinelle Übersetzung, Textgenerierung und Sprachverständnis.
Wo werden Transformer Modelle eingesetzt?
Transformer Modelle finden Anwendung in Chatbots, maschineller Übersetzung, Sprachassistenten, Textzusammenfassungen und vielen anderen Bereichen der künstlichen Intelligenz.


