
Maschinelles Lernen ist eine Schlüsseltechnologie der modernen Datenverarbeitung. Dabei spielen die Methoden Supervised Learning (überwachtes Lernen) und Unsupervised Learning (unüberwachtes Lernen) eine zentrale Rolle. Beide Ansätze haben ihre eigenen Stärken und Schwächen und eignen sich für unterschiedliche Anwendungen. In diesem Artikel erfahren Sie, was hinter diesen Konzepten steckt, wie sie funktionieren und welche Methode am besten zu Ihren Anforderungen passt.
Einführung in Supervised und Unsupervised Learning
Supervised Learning und Unsupervised Learning sind zwei der wichtigsten Ansätze im Bereich des maschinellen Lernens. Beim Supervised Learning wird ein Modell auf Basis eines vorgegebenen Datensatzes mit klar definierten Labels trainiert, während beim Unsupervised Learning ein Modell ohne solche Labels arbeitet und eigenständig Muster in den Daten erkennt. Die Wahl zwischen diesen Methoden hängt von der Art der Daten, den gewünschten Ergebnissen und dem jeweiligen Anwendungsbereich ab.
Was ist Supervised Learning?

Definition und Funktionsweise
Supervised Learning ist ein Ansatz des maschinellen Lernens, bei dem ein Modell mithilfe eines Datensatzes trainiert wird, der bereits mit Labels versehen ist. Ein Label ist dabei die gewünschte Zielvariable oder der „richtige“ Output, den das Modell lernen soll, vorherzusagen. Der Prozess lässt sich in zwei Hauptphasen unterteilen:
- Training: Das Modell wird mit einem Datensatz trainiert, der Input-Daten und die entsprechenden korrekten Outputs enthält.
- Testing: Nach dem Training wird das Modell auf neuen, unlabeled Daten getestet, um seine Vorhersagefähigkeit zu prüfen.
Ein Beispiel hierfür ist die Klassifikation von E-Mails in „Spam“ und „Nicht-Spam“. Hierbei wird ein Modell darauf trainiert, Spam-Mails anhand von vordefinierten Merkmalen zu erkennen.
Beispiele für Supervised Learning
Supervised Learning wird in zahlreichen Bereichen eingesetzt. Hier sind einige Beispiele:
- Bildklassifikation: Modelle werden darauf trainiert, Objekte in Bildern zu erkennen, z. B. die Unterscheidung zwischen Katzen und Hunden.
- Spracherkennung: Systeme wie Sprachassistenten lernen, gesprochene Wörter in Text umzuwandeln.
- Vorhersagen: Finanzmodelle, die auf historischen Daten basieren, können zukünftige Aktienkurse vorhersagen.
- Medizinische Diagnosen: Algorithmen helfen, Krankheiten wie Krebs anhand von Bilddaten zu diagnostizieren.
Vor- und Nachteile von Supervised Learning
Vorteile:
– Sehr präzise Ergebnisse, wenn ausreichend gelabelte Daten vorhanden sind.
– Gut geeignet für spezifische Aufgaben wie Klassifikation und Regression.
– Modelle sind relativ einfach zu interpretieren und zu evaluieren.
Nachteile:
– Erfordert eine große Menge an gelabelten Daten, deren Erstellung zeit- und kostenintensiv sein kann.
– Kann bei neuen, unbekannten Daten versagen, wenn diese außerhalb des Trainingsbereichs liegen.
– Überanpassung (Overfitting) ist bei zu kleinen Datensätzen ein häufiges Problem.
Was ist Unsupervised Learning?

Definition und Funktionsweise
Im Gegensatz zum Supervised Learning arbeitet Unsupervised Learning ohne gelabelte Daten. Stattdessen versucht das Modell, eigenständig Muster, Strukturen oder Cluster in den Daten zu identifizieren. Die Hauptaufgabe besteht darin, Ähnlichkeiten und Unterschiede zu erkennen, ohne dass vorher definiert wird, was genau gesucht wird.
Die bekanntesten Ansätze innerhalb des Unsupervised Learning sind:
- Clustering: Daten werden in Gruppen oder Cluster eingeteilt, z. B. die Segmentierung von Kunden basierend auf Kaufverhalten.
- Dimensionalitätsreduktion: Methoden wie Principal Component Analysis (PCA) reduzieren die Anzahl der Variablen in einem Datensatz, während die wichtigsten Informationen erhalten bleiben.
Beispiele für Unsupervised Learning
Unsupervised Learning wird häufig eingesetzt, wenn keine Labels verfügbar sind oder wenn neue Erkenntnisse aus Daten gewonnen werden sollen:
- Kundensegmentierung: Unternehmen können ihre Kunden in Gruppen einteilen, um gezielte Marketingstrategien zu entwickeln.
- Anomalieerkennung: Modelle erkennen ungewöhnliche Muster, z. B. bei der Betrugserkennung in Finanztransaktionen.
- Empfehlungssysteme: Algorithmen lernen, ähnliche Produkte oder Inhalte zu empfehlen, basierend auf Benutzerverhalten.
- Genanalyse: Entdeckung von Genmustern und -gruppen in biologischen Daten.
Vor- und Nachteile von Unsupervised Learning
Vorteile:
– Keine Notwendigkeit für gelabelte Daten, was Zeit und Kosten spart.
– Kann neue, unerwartete Muster oder Strukturen aufdecken.
– Flexibel einsetzbar für explorative Datenanalysen.
Nachteile:
– Ergebnisse sind oft schwer zu interpretieren.
– Die Modelle können weniger genau sein, da keine „richtige“ Antwort vorgegeben ist.
– Erfordert häufig manuelle Nachbearbeitung, um die gefundenen Muster zu validieren.
Die wichtigsten Unterschiede auf einen Blick
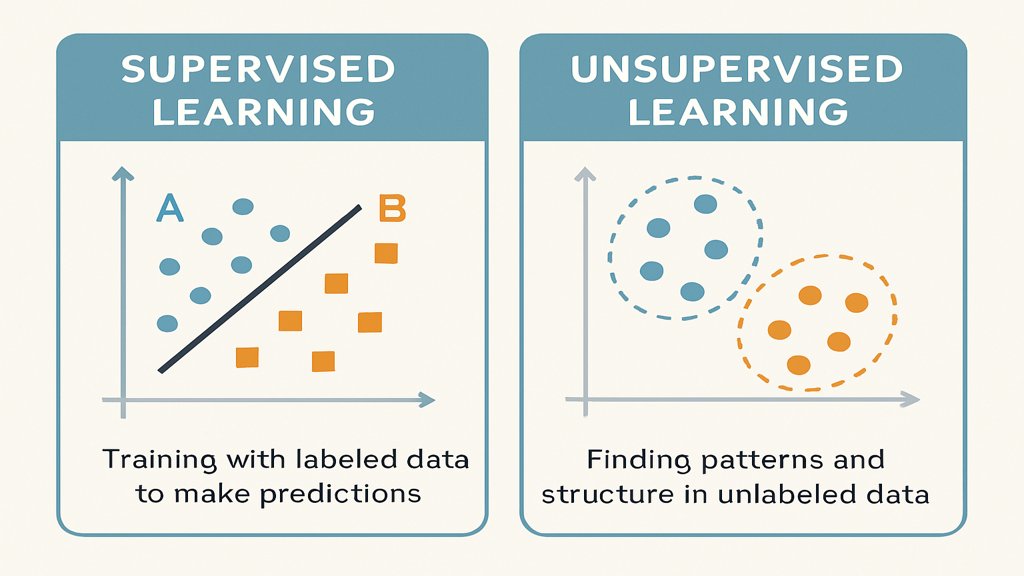
Vergleich der Datenanforderungen
Supervised Learning benötigt gelabelte Daten, um präzise Modelle zu trainieren. Diese Labels sind oft teuer und aufwendig zu erstellen. Unsupervised Learning hingegen arbeitet mit rohen, unlabeled Daten und ist daher ideal für Szenarien, bei denen Labels fehlen oder schwer zu definieren sind.
Vergleich der Anwendungsbereiche
Supervised Learning wird häufig für Aufgaben wie Klassifikation, Regression und Vorhersage eingesetzt. Es eignet sich für Anwendungen, bei denen klare Zielvorgaben existieren. Unsupervised Learning wird hingegen verwendet, um neue Muster oder Strukturen zu entdecken, z. B. bei der Kundensegmentierung oder Anomalieerkennung.
Vergleich der Komplexität
Supervised Learning-Modelle sind in der Regel einfacher zu interpretieren, da die Zielvariable klar definiert ist. Unsupervised Learning kann komplexer sein, da die Modelle eigenständig Muster finden müssen, deren Bedeutung oft erst im Nachhinein analysiert wird.
Anwendungsbereiche und Entscheidungshilfen
Wann Supervised Learning wählen?
Wählen Sie Supervised Learning, wenn:
– Sie klare Zielvorgaben haben, z. B. eine Klassifikation oder Vorhersage.
– Sie Zugang zu gelabelten Daten haben.
– Präzision und Genauigkeit für Ihre Anwendung entscheidend sind.
Beispiele: Spam-Filter, medizinische Diagnosen, Aktienkursprognosen.
Wann Unsupervised Learning wählen?
Unsupervised Learning ist ideal, wenn:
– Keine gelabelten Daten verfügbar sind.
– Sie explorative Analysen durchführen möchten, um neue Muster zu entdecken.
– Sie Einblicke in komplexe Datensätze gewinnen möchten.
Beispiele: Kundensegmentierung, Betrugserkennung, Genanalyse.
Kombination beider Ansätze
In vielen Fällen kann eine Kombination aus Supervised und Unsupervised Learning sinnvoll sein. Beispielsweise können unüberwachte Modelle genutzt werden, um Daten zu strukturieren, die anschließend in einem überwachten Lernprozess verwendet werden. Diese hybride Herangehensweise wird zunehmend bei komplexen Aufgaben wie der Verarbeitung großer Datensätze eingesetzt.
Fazit: Welcher Ansatz passt zu Ihren Anforderungen?
Die Wahl zwischen Supervised und Unsupervised Learning hängt von Ihren spezifischen Anforderungen, der Verfügbarkeit von gelabelten Daten und dem gewünschten Ergebnis ab. Wenn Sie klare Zielvorgaben haben und präzise Vorhersagen benötigen, ist Supervised Learning die richtige Wahl. Für explorative Analysen und die Entdeckung neuer Muster eignet sich Unsupervised Learning besser. In vielen realen Anwendungen können beide Ansätze kombiniert werden, um die besten Ergebnisse zu erzielen. Analysieren Sie Ihre Daten und Ihre Ziele sorgfältig, um den passenden Ansatz für Ihre Bedürfnisse zu finden.
Erfahren Sie mehr über Machine Learning für Manager, um ein tieferes Verständnis für die Grundlagen und Anwendungen des maschinellen Lernens zu erhalten. Wenn Sie an spezifischen Anwendungsfällen interessiert sind, könnten auch Predictive Analytics Use Cases oder die Anomalieerkennung für Sie von Interesse sein.
FAQ zum Thema Supervised vs unsupervised learning
Was ist der Hauptunterschied zwischen Supervised und Unsupervised Learning?
Der Hauptunterschied liegt darin, dass Supervised Learning mit gelabelten Daten arbeitet, während Unsupervised Learning selbstständig Muster in ungelabelten Daten erkennt.
Welche Anwendungsbereiche gibt es für Supervised Learning?
Supervised Learning wird häufig für Klassifikationsprobleme, Prognosen und Regressionen verwendet, z. B. in der Bilderkennung oder Finanzanalyse.
Wann sollte Unsupervised Learning eingesetzt werden?
Unsupervised Learning eignet sich, wenn keine gelabelten Daten verfügbar sind und Muster oder Gruppen in den Daten erkannt werden sollen, z. B. in der Kundensegmentierung.


